Python爬虫库概述
在Python编程中,爬虫是一个常用的功能,用于从网站上抓取数据。Python拥有多种强大的爬虫库,它们各具特色,适用于不同的爬虫需求。以下是对几种常用Python爬虫库的比较。
- Requests库
Requests 是一个简单易用的HTTP库,它让我们能够轻松地发送HTTP请求。它支持HTTP/1.1,并且非常易于使用,适合于进行简单的网页爬取。
优点:
简单易用,适合初学者。
支持多种HTTP方法,如GET、POST等。
自动处理cookies和session。
缺点:
对于复杂的爬虫任务,功能相对有限。
- Scrapy库
Scrapy 是一个强大的爬虫框架,它提供了一个完整的爬虫生态系统。Scrapy非常适合于大规模的网站抓取和数据处理。
优点:
高效的爬虫引擎,适合大规模数据抓取。
提供丰富的中间件和扩展。
支持分布式爬虫。
缺点:
学习曲线较陡峭,需要一定的编程基础。
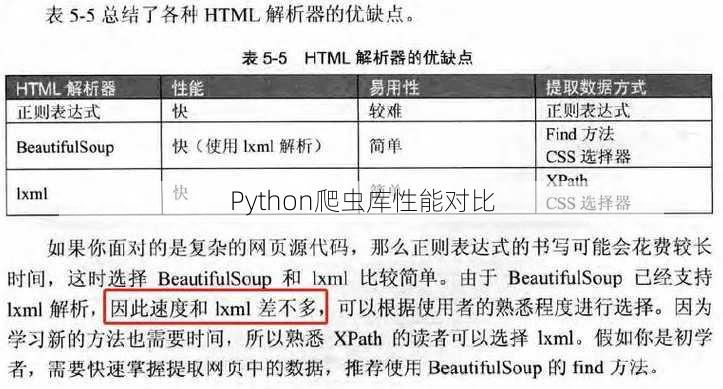
- BeautifulSoup库
BeautifulSoup 是一个用于解析HTML和XML文档的库,它可以帮助我们快速地从网页中提取数据。
优点:
解析HTML和XML文档非常方便。
提供了丰富的DOM树遍历方法。
支持多种解析器。
缺点:
对于动态加载的网页,解析效率较低。
- Selenium库
Selenium 是一个用于自动化Web浏览器的工具,它可以模拟用户的操作,如点击、输入等。
优点:
可以模拟真实用户的操作。
支持多种浏览器。
适合于需要登录、点击等交互的爬虫任务。
缺点:
性能相对较低,不适合大规模爬取。
- Pyppeteer库
Pyppeteer 是一个基于Python的Node.js的浏览器自动化框架,它提供了对浏览器操作的接口。
优点:
性能高,可以模拟真实用户操作。
支持多种浏览器。
适用于需要动态交互的爬虫任务。
缺点:
学习曲线较陡峭。
相关问题及回答
- 问题:Requests库和Scrapy库有什么区别?
回答:Requests库是一个简单的HTTP库,适合进行简单的爬虫任务;而Scrapy是一个强大的爬虫框架,适合进行大规模的网站抓取和数据处理。
- 问题:BeautifulSoup库适合处理哪些类型的网页数据?
回答:BeautifulSoup库适合处理静态HTML和XML文档,它可以帮助我们快速地从网页中提取数据。
- 问题:Selenium库和Pyppeteer库哪个更适合进行自动化测试?
回答:Selenium库更适合进行自动化测试,因为它可以模拟用户的操作,如点击、输入等。
- 问题:在爬取数据时,如何避免被网站封禁?
回答:在爬取数据时,应遵守网站的robots.txt文件规定,合理设置爬取频率,避免对网站造成过大压力。
- 问题:Scrapy库中的中间件有什么作用?
回答:Scrapy库中的中间件可以用于处理请求和响应,如添加headers、处理cookies、重试请求等。